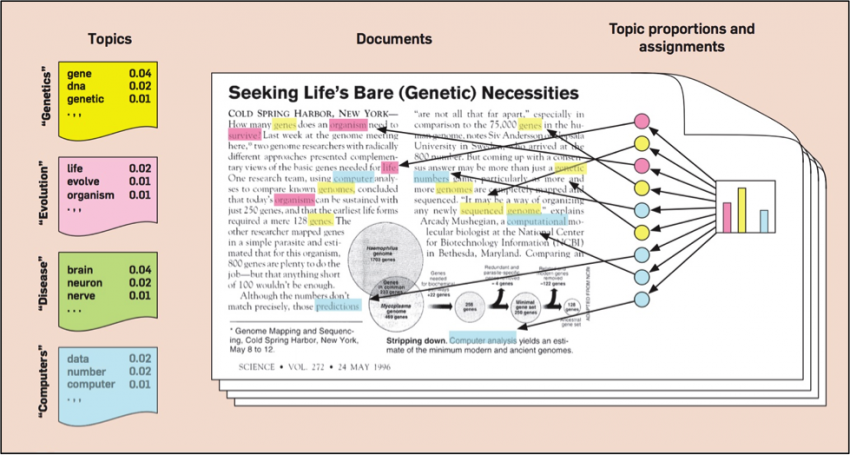
A recent prediction that algorithmic curation would be one of the major trends of 2016 got me thinking about news recommendation engines. I’ve always been curious about the technology so I recently started digging into what makes them work and realized there is a whole lot to learn. But a little research and conversation with a newsroom technologist at New York Times helped me to understand how they work.
First you should know that the basics are easy enough to understand even if the code and academic articles are beyond your grasp, as they were to me. In fact, a recommendation system is a little like a librarian. If she knows you, she can recommend a book based on your interests; if she doesn’t, she can recommend best sellers that everyone seems to be reading. These two scenarios are closely related to the main types of recommendation engines.
Content-based recommendations
Traditionally, news websites have used tags to categorize their content. Every time an article is published, editors add a tag or multiple tags to it that describes the content and makes it easy for computers to categorize. At it’s most basic, a content-based filter would recognize that you read articles tagged “food”, and then recommend other “food” articles. This system is similar to the librarian going pointing you to the young adult or mystery section of the library because she knows where your interests lie.
More sophisticated content-based filtering systems go beyond article tags, and use natural language processing and other techniques to get a deeper understanding of both the story and the reader. The Washington Post’s Clavis tool is one good example.
Collaborative filtering
Collaborative filtering recommends content based on your past reading habits and other people like you. If an article is popular with readers like you, a collaborative filter is likely to recommend it. In the library example, a librarian who knows your interests are similar to another student can recommend you read books that the other student liked.
This method uses the reading history of one reader to recommend articles to another one who has the same preferences or reading history. So if you are consuming content related to technology, you will be recommended what other tech-geeks are reading on the web.
Hybrid filtering and the New York Times' system
Many recommendation systems combine content-based filtering with collaborative filtering to produce what’s known as the hybrid-filtering system. Hybrid systems base their recommendations on both the content of the article, as well as who is reading that article and how popular it is.
While researching this post, I came across an explainer of the New York Times' system by Alexander Spangher, a data-scientist at NYT, that helped me to understand how it works. The first thing to note is that hybrids help frequently make better recommendations than content-based or collaborative filters alone, which is why they power many news recommendation engines.
The NYT uses a natural language processing technique called Latent Dirichlet Allocation that allows computers to figure out what an article is about by counting the number of times a particular word appears and comparing that count to other articles, according to Spangher's post. LDA can also help weigh how much of an article is devoted to a particular topic, which allows the system to categorize an article, for instance, as 50% global warming and 40% politics.
The NYT system also checks to make sure recommended articles aren't too old or outdated. The assessment checks for the "evergreenness" of each article by looking at “a number of article-features like word-count, frequency of updates, and even the presence of specific words like 'announce' or '<day-of-week>' to predict how long each article will stay fresh in the candidate pool of articles to be recommended,” Spangher said.
One problem with the LDA approach is deciding topics in articles in which the number of times a word appears in a story is not always an accurate reflection of the topic of that story. Think about satirical articles that use metaphors or puns, or articles about different places that have the same name. In these cases, NYT’s recommendation-engine uses the information on who is reading that article (collaborative filtering). If an article is identified through LDA as containing 20% politics and 80% family, but is primarily read by readers interested in 90% politics, the recommendation-engine would adjust the categorization of the article using both these percentages.
Understanding readers
So how does NYT decide that the readers are interested in 90% politics? They use the simple method of applying topic-modelling on the articles you have read. If you read seven articles in a week, NYT recommendation-engine would use numerical average of the topics in those seven articles to decide what your interests are.
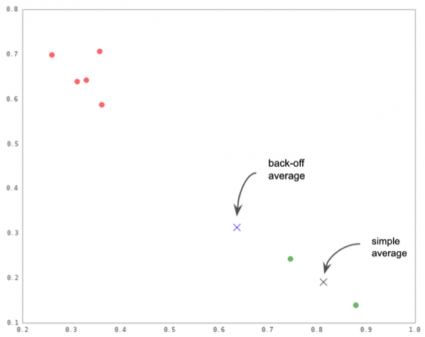
But wait! What if you did not like three of those seven articles you read? Or maybe you clicked on them but never really read them? And what about the articles you never clicked? The simple answer is that there is no way for a recommendation-engine to completely account for such actions. However, to make the system more efficient, NYT applies the technique of what they call the back-off approach. This approach assumes that you “90% like” the article you clicked, and “10% like” the article you did not. The recommendation system would then use these values to weigh topics of your interest, resulting in a more conservative average than the one simple numerical calculations would produce.
The NYT is constantly updating their article-recommendation system and testing new models, Spangher said. One model they plan to further develop in future is weighing different reader behaviors like scroll-depth, dwell-time and social-share to better understand reader preferences. According to Spangher, “results show scroll-depth of 50% to be more indicative of interest than scroll-depth of 100%, which we assume relates to knowledgeable readers not needing to read a full piece.”
The NYT Developers team also plans to enhance their recommendation system by introducing sequence recommendations. “For example,” Spangher explained, “if on cooking.nytimes.com, we see that you are a steak person, we might not want to recommend the top N steak recipes. Rather, a steak recipe followed by a dessert, then a wine pairing might create a better experience.”
Each news organization publishes hundreds of articles and blog posts every day, and as more and more content is produced online, it is important for these organizations to filter the online content to ensure they can direct the most relevant articles to each individual user. “We want to provide the most relevant news and information to our readers so they stay longer and read more,” Spangher added. “Recommendation engine is part of The Times's strategy to engage readers.”




