This past Fall, I spent time with the NPR News Apps team (now known as NPR Visuals) coding up some projects, working mainly as a visual/interaction designer. But in the last few months, I’ve been working on a project that involves scraping newspaper articles and Twitter APIs for data.
I was a relative beginner with Python — I’d pair coded a bit with others and made some basic programs, but nothing too complicated. I knew I needed to develop a more in-depth knowledge of web scraping and data parsing skills and of course took to the web to help. Along the way, I found a few tools that were exceptionally useful for expanding my knowledge. So if you too are just starting out with scraping, here are five of the most useful tools I’ve encountered while learning and working on my project.
1. Scraper
A free Chrome browser extension, Scraper is a handy, easy-to-use tool when you need to extract plain text from websites. After downloading and installing it, just highlight the part of the webpage you’d like to scrape, right click, and then choose “Scrape similar…”. And just like that, a window will pop-up with information that’s similar to what you just highlighted, already rendered and ready to be exported to Google Docs.
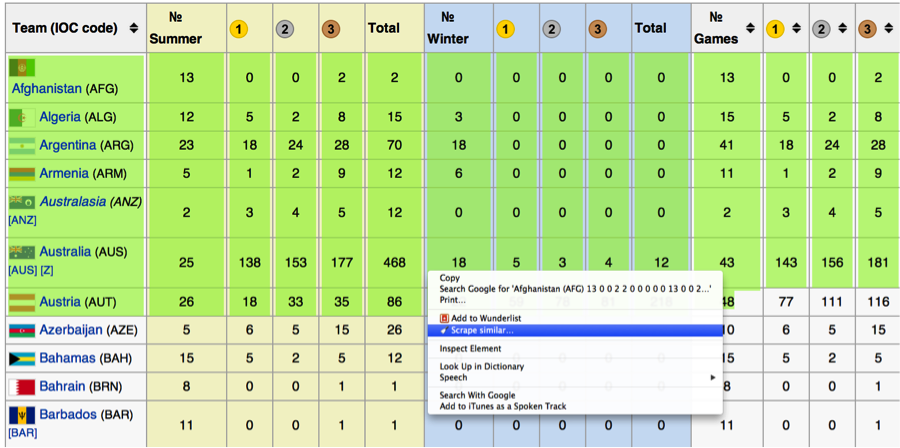
Scraper is best for plain-text extraction, so don’t expect to be able to scrape images or more complicated objects. It also doesn’t perform great on a huge volume of text, but it’s very easy and fast to use, especially for a beginner. Heads up: It uses XPath to determine which parts of the page’s structure to scrape, though the developers have also included jQuery selectors recently. You can get by without that knowledge, but it’s more powerful if you have a decent grasp of the code.
2. Outwit Hub
Outwit Hub is another browser extension you can get for free, though this time for Firefox. It’s a pretty robust product among the free ones that exist, especially because it can work for both advanced and beginner users. More advanced users can specify exactly what they need to extract, but beginner users can simply choose to download all the PDFs, images, or documents, etc. listed on a given page.
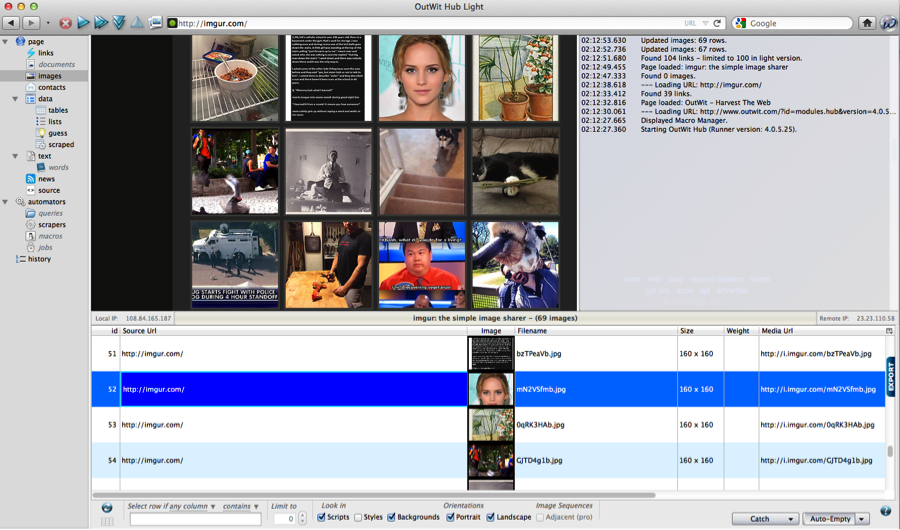
It also returns the scraped data in a visual presentation, so complete non-coders will have an easy time understanding what’s being returned. Extracted data can be exported into a variety of formats, and images/documents can be saved directly to your hard drive. They also have some tutorials online for those who need additional help.
3. Scraperwiki (Classic version here)
Scraperwiki has updated its platform recently. While they still allow experienced coders to run their own code in-browser, they’ve moved more into custom- and pre-made tools for beginner coders (e.g. Pre-made tools to scrape Twitter).
These tools can be pretty useful if you don’t have any coding knowledge, but what happens if you’re in that in-between stage? You know, the one where you’ve coded before, but you’d still like a guide before coding a scraper on your own. Well, that’s where classic Scraperwiki comes in.
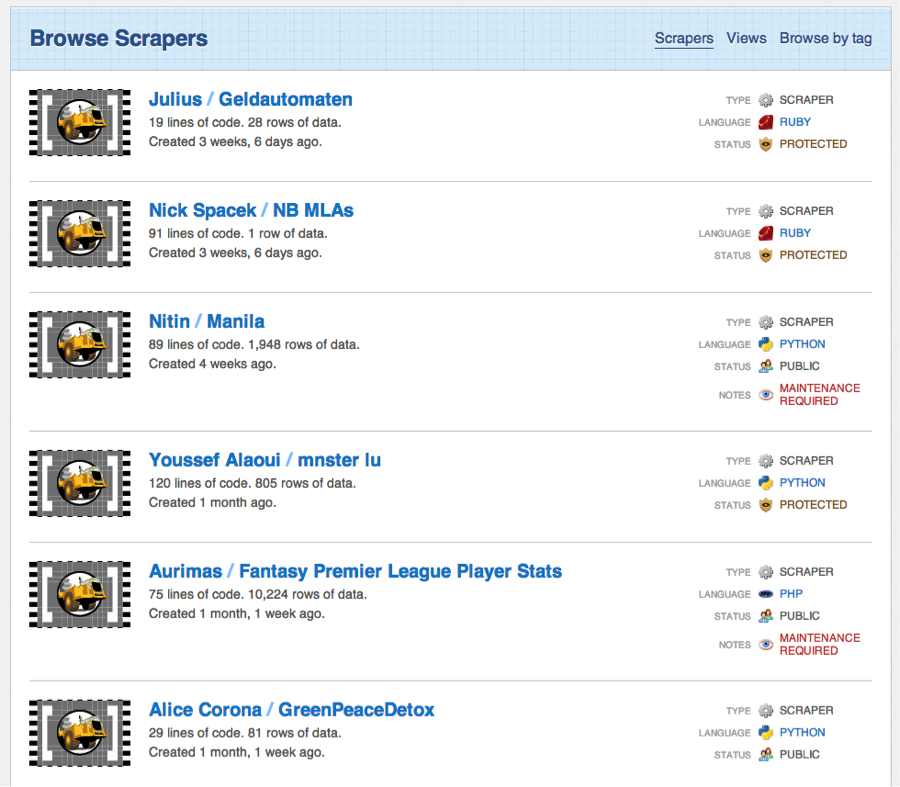
Classic Scraperwiki allows you to browse scrapers that others have written, which means you can also grab scrapers that target the same data you want, saving you some time. But that archive is most useful if you need a solid way to see how others put together code. It’s a great resource for learning how to do your own scrapes and one day writing your own code from scratch.
4. BeautifulSoup
A parsing library for Python, BeautifulSoup delves more into code than the previous options, but still does so with clear, easy-to-understand methods for navigating, searching, dissecting, and finally extracting the data that you need. It doesn’t take too much code to grab some data, and the installation’s pretty swift too. You’ll need to use the command line. But if you’ve never used your terminal before, don’t get intimidated! Here’s how you can do it. I’m going to assume you’ve already installed Python. First, we’re going to install pip, which is almost like an app store for Python code. With that in mind, open up your terminal and type in:
$ sudo easy_install pip
Press enter. Voila! Pip should be installed. Then, install BeautifulSoup with pip:
$ pip install beautifulsoup4
Ultimately, it does a pretty good job of fetching contents from a given URL and allows you to parse data without much hassle. You’ll want to come into this with some knowledge of Python, but if you’re looking to move on from ready-made tools and to create code that grabs exactly what you need, BeautifulSoup is a good place to start.
5. Scrapy
Similar to BeautifulSoup, Scrapy also delves further into writing your own code. However, Scrapy is more robust and acts as a full-scale web-spider or web scraper framework. On the other hand, BeautifulSoup can be limited by your designated URL unless you set up an infinite loop manually.
Scrapy is a Python package that can be installed via pip just like BeautifulSoup:
$ pip install Scrapy
In my opinion, Scrapy has a steeper learning curve than BeautifulSoup, but it does have more features. For example, since it’s a full framework, it has full unicode, redirection, handling, etc. It also has incredibly thorough documentation, so if you’re willing to push your code a bit further, you can do a lot with Scrapy.
Now that you have these tools, start digging around the Internet to find something you’re interested in. Whether you just want a simple way to compile info into a Google doc or to start manipulating data yourself, there’s always a tool to help you. Have fun, data and hacker journalists!
About the author





