
On Sunday, March 2, Knight-Mozilla OpenNews, the Newseum and Pop Up Archive hosted a one-day conference focused on solving a fairly new problem: How to preserve the new breed of complex interactive projects that are becoming more prevalent in news. While print newspapers are relatively well-preserved, we as an industry do a poor job of preserving interactive databases and online data visualizations, and they are in danger of being lost to history.
Inside newsrooms, these interactive databases are sometimes called “news applications” — but don’t be confused. They’re interactive databases published on the web, not something you buy on your smartphone. Think Dollars for Docs, not not Flipboard or Zite.
We were among a few dozen attendees who attended the meeting. Preserving interactive databases isn’t as easy as storing a digital copy. They’re far more complex than a printed newspaper, with technical requirements and external dependencies that make preservation anything but straightforward.
The conference split into small groups to start with some basic questions. One group tackled best practices. Another talked about how external dependencies like the Google Maps API could be handled, while another asked who might be willing to pay archiving efforts, and how to make it inexpensive so cash-strapped newsrooms can do it. Our group, consisting of Elaine Ayo, Mohammed Haddad, Tyler Fisher, Jacob Harris, Scott Klein, Roger Macdonald, Mike Tigas and Marcos Vanetta was tasked with answering the very basic question, “What is a news app and what is one made of?” Our goal was to define the components of a news app to better facilitate the conversation around what is worth preserving, what needs to be virtualized, and what it might take to archive one.
The conceptual model we took as an inspiration was the Open Systems Interconnection Model, usually called “The OSI Model,” one of the frameworks that makes the low-level networking bits of the Internet work without a lot of coordination. We attempted to come up with a way to describe news apps using OSI-like “layers,” with infrastructure at the bottom and audience at the top. Like the OSI Model, we conceived each layer as talking exclusively to the layer above and below it. But the metaphor broke down. We found that too many parts of news applications worth preserving — the code we write, the processes we define — talk to lots of layers at once.
So we ditched the layers idea and started to think about interdependent, non-hierarchical categories. We defined six of them, each with artifacts, attributes and preservation requirements.
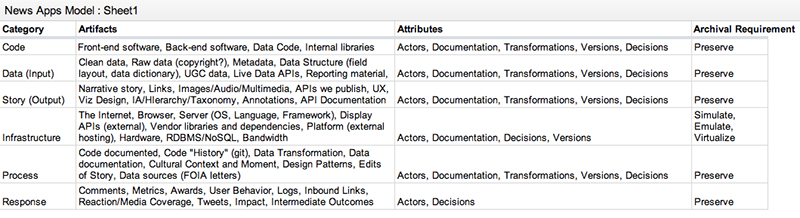
Our draft model includes six categories:
- The Code Category includes the software that runs in production as well as the software used to acquire, parse and analyze the data and any libraries the newsroom wrote for its own use.
- The Data Category might better be called the Input Category. It includes data (raw and cleaned), metadata and data structure artifacts like the data dictionaries, reporting material and more.
- The Story Category, also called the Output Category includes the narrative stories that went along with the app, APIs published with the app, multimedia, UX, visual design, information architecture, annotations and documentation.
- The Infrastructure Category, which is something to be simulated more than preserved, includes the Internet itself (bandwidth), web browsers, web servers, operating systems, programming languages and frameworks, external display APIs, vendor libraries and dependencies and database management systems
- The Process Category includes code documentation, code history (git), data transformation diaries, data diaries and documentation, documents describing the cultural context, story edits, data sources such as FOIA letters and general writing about process (e.g., a nerd blog)
- The Response Category includes user comments, site metrics, awards won, user behavior metrics, logs, media coverage, tweets and other social media mentions, as well as real-world impact
- Every category has actors, or people who perform tasks on this category. When archiving, ask who those actors were and what decisions they made. Save versions of each artifact to show how something transformed over time. And of course, provide documentation for all of these things.
Perhaps this all seems laborious or trivial, but knowing exactly what goes into and comes out of a news application is fundamental to understanding how to preserve one.
The model is not so much a way to think about how to build news apps — though it certainly does strongly imply something about how they’re built — as it is a way to understand them as human-made objects, and how to break them down in order to preserve them. Separating “code” from “infrastructure” and “data” is not all that helpful when building, but preserving each category requires separate and intentional efforts, different skills and technologies.
Throughout the day, we continued to return to Adrian Holovaty’s chicagocrime.org, a groundbreaking news application that is now lost to the world. What do we want to know in 2014 about that app? What would we want to know in 2034? It’s not just the code that Adrian wrote or the map itself, though his reverse engineering of the Google Maps Flash API was one of its great innovations when it first came out. We want to know about his process. We want to know the infrastructure on which he built the app (indeed, making his use of Google Maps even more impressive). We want to know about how it was designed, how the user interactions worked. We want to know the impact it had and who responded to it.
With a defined model of news applications, it becomes clear that archiving a news app is about more than just making sure the app still exists on the web. Things like oral histories and screencasts will likely be required to tell future news developers and historians how this kind of journalism came to be and why we made the decisions we made.
This is just a first stab at the model. Our draft is the result of a few hours’ effort and we’ve posted it to GitHub. We hold no monopoly on the idea. Feel free to fork it and send us pull requests and to open issues to give us better ideas.
Eventually, we hope this model can serve as a document for understanding how to preserve a news application, and to start a conversation about how to tackle each part. Preserving our work for future generations is crucial. Just as we can look at a New York Herald issue from the middle of the Civil War, even though the Herald itself and everybody associated with it has long since died, we hope that future news nerds can look at the work we do long after we’re gone. The challenge is great, but monumentally important.
About the author





